

Technologies
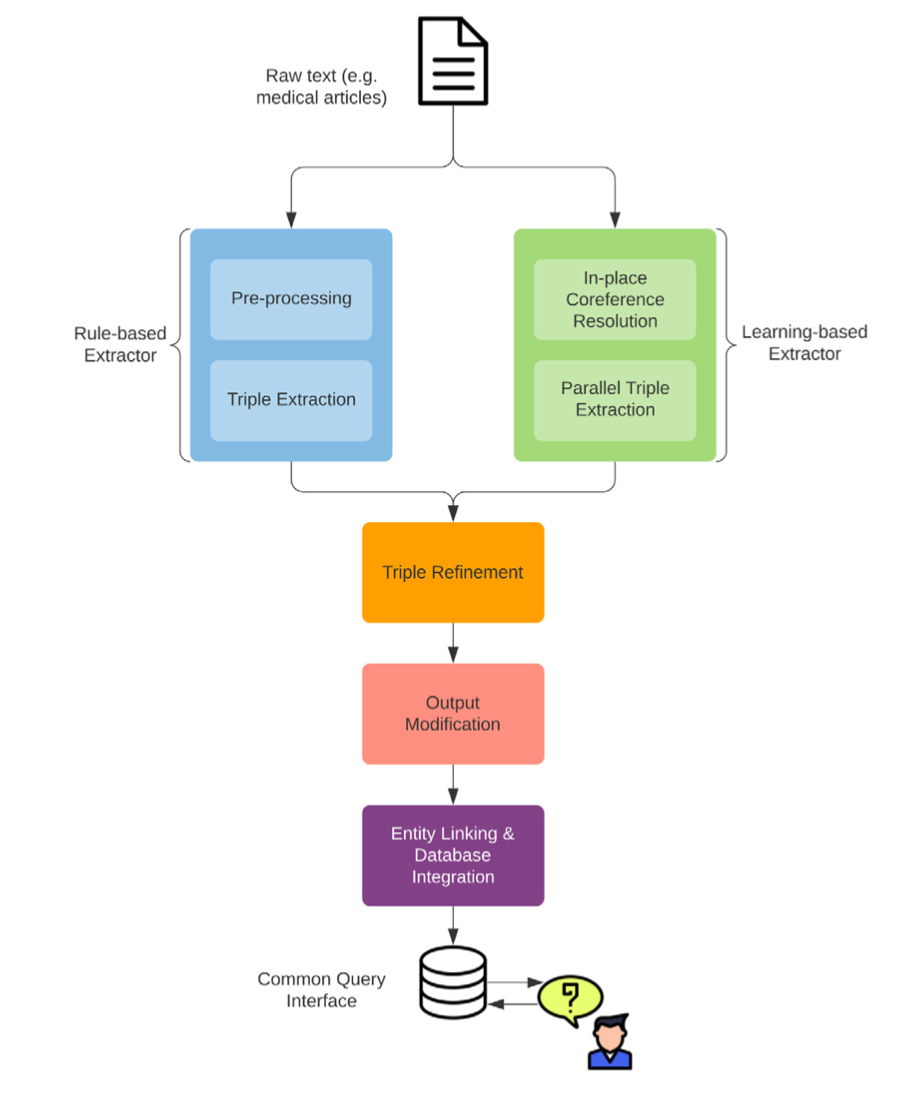
Search Over Relational Databases (SODA) is a pattern-based keyword search system for relational databases. Starting from a keyword query, SODA automatically generates a ranked list of interpretations in the form of executable SQLs. The key idea behind SODA is to use a graph pattern matching algorithm over the metadata model of the data warehouse. The components of a data warehouse are illustrated in Figure 1. More precisely, the key innovation of SODA is the use of patterns that help to interpret and exploit a large variety of different kinds of metadata such as homonyms and synonyms (e.g., using DBPedia), domain ontologies, modeling conventions (e.g., inheritance) and last but not least base data.
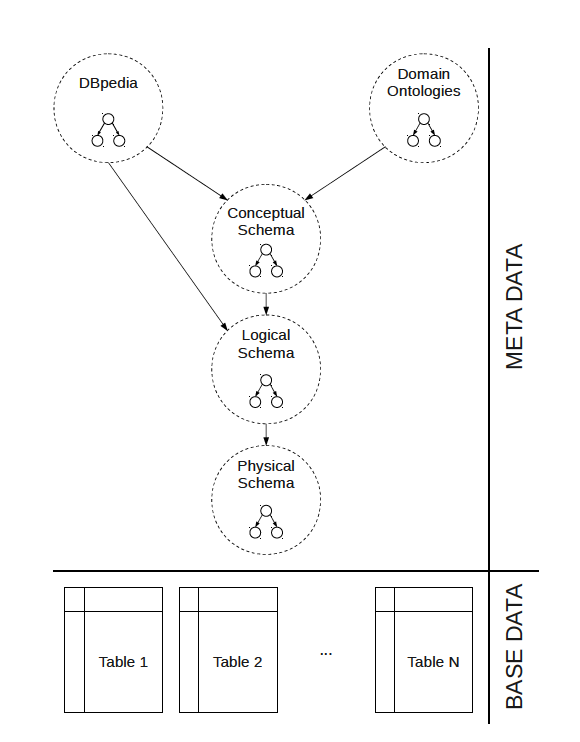
The main steps involved in the keyword search translation process are the following (the algorithm is illustrated in Figure 2):
Lookup: matches keywords to entry points in the metadata graph
Rank and top N: assigns a score to each result and continues with the best N candidate results
Tables: Identifies all tables in the relational database that are used in a candidate solution and discovers the relationships between these tables (joins)
Filters: discovers filters on the previously identified tables and columns (a filter condition would be “Zurich” on an example table “Address” and column “City”)
SQL: generates a list of executable query statements based on the information collected in all previous steps.
The strengths of SODA are the use of metadata patterns and domain ontologies, which allow defining concepts and including domain specific knowledge. In addition, the inclusion of external sources like DBpedia for homonyms and synonyms is beneficial for improving the quality of the search results.
Reference:
Blunschi L, Jossen C, Kossmann D, Mori M, Stockinger K. Soda: Generating sql for business users. Proceedings of the VLDB Endowment. 2012 Jun 1;5(10):932-43.


This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 863410


