Blog
Data Exploration (DE) can be defined as the act of querying, searching and analyzing data in an iterative manner. What makes it an appealing research topic is its evolving nature.DE has seen multiple incarnations over time that depend on the type of data being analyzed (e.g., structured data, text, graphs), the individual operations it relies on (e.g., selection, transformation, visualization), and the expertise of who is exploring data (e.g., domain expert, data scientist). This has given rise to multiple approaches that vary in computational complexity and in the amount of guidance they provide.
Exploratory Data Analysis (EDA) leverages DE to achieve a goal. Think of DE as the framework that EDA builds on. EDA caters to realistic situations where users are only partially familiar with data and its structure, or where they do not know precisely what they are looking for. In that context, users need a dialogue with the data to refine their understanding and their needs. Relying on DE alone in that case would require a large number of user requests, thereby resulting in a considerable amount of time and human effort. The role of data managementis hence to bridge the gap between the amount of data to be explored and limited human ability, and provide efficient and effective approaches to retrieve data and refine user needs.
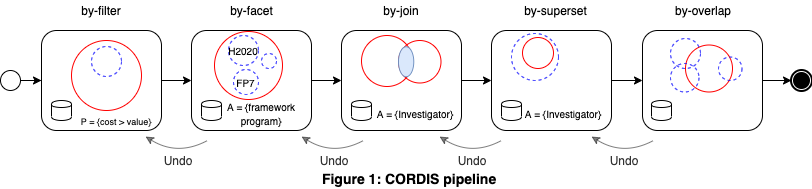
Pipelines and scenarios. EDA is enabled by pipelines. A pipeline is a series of operations, each of which constitutes an atomic request. In the first example (Figure 1), Guillem, an EU policymaker wants to explore the CORDIS dataset to understand the participation of different investigators in EU-funded projects. Guillem starts by filtering projects on cost. Then, he splits them results by framework program. After selecting one subset (H2020 projects, for example) Guillem requests their PIs with a by-join. He notices that the returnedset is small and asks to expand it with by-superset. At the end, he asks for overlapping projects to explore.
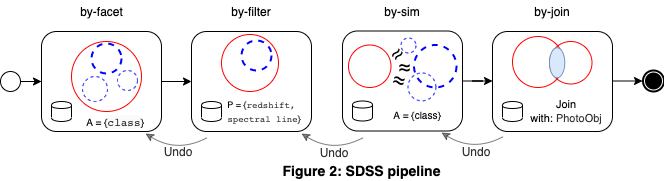
In Figure 2, Sri, an astrophysicist, explores astronomical objects in SDSS, a large sky survey database. Sri needs pipelines to find objects of interest in the specObj table, she starts by grouping the objects according to their class, (by-facet on class), she selects one class and filter the objects using a predicate (by-filter on some attributes), then she explores other groups that are similar to the last selected one (by-sim). Finally, she wants to extend the schema by adding some attributes from the table PhotoObj (using by-join).
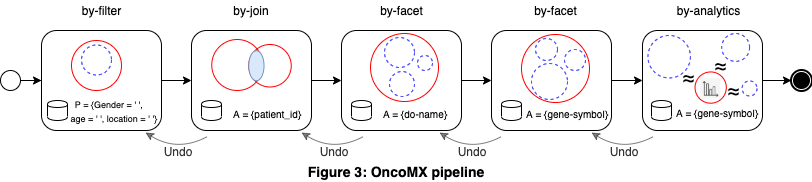
The pipeline in Figure 3 is created by Fred, a biologist who studies cancer patients. Fred starts by selecting patients with some demographics, then uses a join to find the type of cancer they have along with associated genes. The two by-facet operations help her explore subsets according to cancer type and to gene. Finally, the last operation explores other cancer types with similar gene symbols.
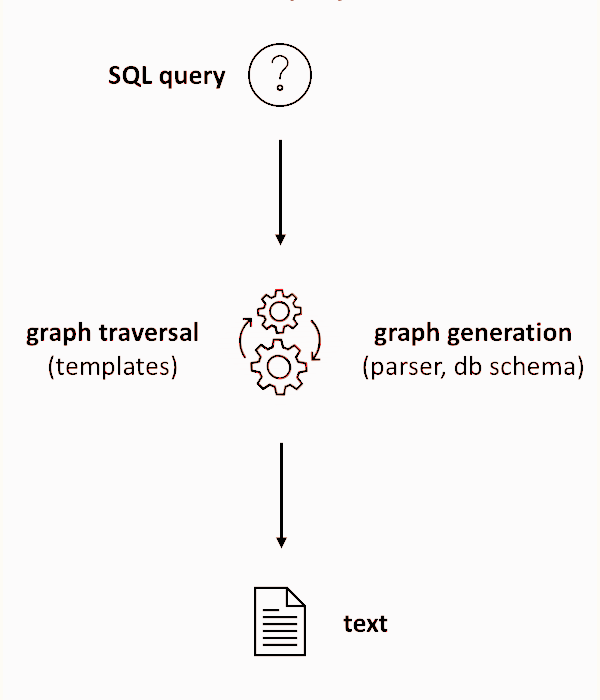
All the operations used in our pipelines are instances of by-example, a powerful operation that takes an example set as input and returns k other sets. By-example operations operate at a set level as discussed in [1]. Individual operations could be expressed using a high level algebra, such as the one used in the above examples, or a natural language query, a SPARQL query, a SQL query, etc. In practice, only a small number of users can build pipelines from scratch. This creates a new research opportunity: generating exploration pipelines.
Generating Exploration Pipelines. The problem of generating exploration pipelines can be approached in different ways depending on the user’s expertise and willingness to provide feedback. In a scenario where a pipeline is defined and needs to be instantiated during exploration, the problem could be cast as finding the right parameters for each operation. In a scenario where the user is typing the next operation, it could be seen as a query completion problem. In a scenario where the user does not write exploration operations and only provides feedback on results, it could be seen as the problem of learning the user’s pipeline. All these cases result in fully-guided or partially-guided exploration.
Full-Guidance with Reinforcement Learning. RL is used in two upcoming publications ([4] and [5]) to generate exploration pipelines based on a simulated agent experience. Both works rely on modeling a pipeline as a Markov Decision Process. In [4], a Deep RL architecture is used for generating notebooks that show diverse aspects of a dataset in a coherent narrative. In [5], an end-to-end exploration policy is generated to find a set of users in a collection of user groups. The framework accepts a wide class of exploration actions and does not need to gather exploration logs. An open question in INODE is the applicability of this framework to our datasets and scenarios described above.
Partial Guidance with Active Learning. In this context, the database is viewed as a set of records, and the user is asked to label some of them as “interesting” or “not interesting”. AL is claimed to be superior to faceted search. Systems like AIDE [2] and REQUEST [3] assist users in constructing accurate exploratory queries, while at the same time minimizing the number of sample records presented to them for labeling. Both systems rely on training a decision tree classifier to build a model that classifies unlabeled records. Decision trees are mapped to range queries where the path to a leaf node is interpreted as a hyper-rectangle representing predicates that capture a data region of interest to the user. An example of such queries is: SELECT * FROM laptops WHERE price>$500 AND price≤$860AND screen≥11” AND screen<14”. In INODE, we are studying the applicability of this framework to generating exploration pipelines.
References
[1] Behrooz Omidvar-Tehrani, Sihem Amer-Yahia, Ria Mae Borromeo: User group analytics: hypothesis generation and exploratory analysis of user data. VLDB J. 28(2): 243-266 (2019)
[2] Kyriaki Dimitriadou, Olga Papaemmanouil, Yanlei Diao: AIDE: An Active Learning-Based Approach for Interactive Data Exploration. IEEE Trans. Knowl. Data Eng. 28(11): 2842-2856 (2016)
[3] Xiaoyu Ge, Yanbing Xue, Zhipeng Luo, Mohamed A. Sharaf, Panos K. Chrysanthis: REQUEST: A scalable framework for interactive construction of exploratory queries. BigData 2016: 646-655
[4] Ori Bar El, Tova Milo, Amit Somech: Automatically Generating Data Exploration Sessions Using Deep Reinforcement Learning. SIGMOD Conference 2020: 1527-1537
[5] Mariia Seleznova, Behrooz Omidvar-Tehrani, Sihem Amer-Yahia, Eric Simon: Guided Exploration of User Groups. PVLDB 2020 (to appear)


This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 863410